
README_zh.md 32 KB

🌐 博客 • ⏬ 下载模型 • 🪧 样例演示 • 💬 讨论 • ✉️ 邮箱 • 💬 谷歌群组 or 微信群
• 📃 论文(敬请期待)
GLM-130B:开放的中英双语预训练模型
摘要:何为 GLM-130B?
GLM-130B 是一个开源开放的双语(中文和英文)双向稠密模型,拥有 1300 亿个参数,模型架构采用通用语言模型(GLM)。它旨在支持在一台 A100(40G * 8) 或 V100(32G * 8)服务器上对千亿规模的参数进行推理。截至 2022 年 7 月 3 日,GLM-130B 已经对超过 4000 亿个文本标识符(中文和英文各 2000 亿)进行了训练,它有以下独特优势:
- 双语:同时支持中文和英文。
- 任务表现(英文): 在 LAMBADA 上优于 GPT-3 175B(+4.0%)、OPT-175B(+5.5%)和 BLOOM-176B(+13.0%),在 MMLU 上略优于GPT-3 175B(+0.9%)。
- 任务表现(中文):在 7 个零样本 CLUE 数据集(+24.26%)和 5 个零样本 FewCLUE 数据集(+12.75%)上明显优于 ERNIE TITAN 3.0 260B。
- 快速推理:支持用一台 A100 服务器使用 SAT 和 FasterTransformer 进行快速推理(速度最高可达2.5倍)。
- 可复现性:所有的结果(超过30个任务)都可以用我们开源的代码和模型参数轻松复现。
- 多平台:支持在 NVIDIA、Hygon DCU、Ascend 910 和 Sunway 处理器上进行训练与推理(代码即将开源)。
快速上手
环境配置
我们的代码是建立在 SAT 之上的。我们推荐使用 Miniconda 来管理环境并通过 pip install -r requirements.txt 来安装额外的依赖包。以下是我们推荐的环境配置:
- Python 3.9+ / PyTorch 1.10+ / DeepSpeed 0.6+ / Apex(需要安装包含 CUDA 和 C++ 扩展的版本,参考资料)
建议使用 A100(40G * 8)服务器,因为所有报告的评估结果(约30个任务)都可以用一台 A100 服务器在大约半天内轻松再现。GLM-130B 也可以在具有较小 GPU 内存的服务器上进行推断,例如具有 V100(32G * 8)的服务器。详见 Low-resource Inference。
从 这里 申请下载 GLM-130B 的模型检查点,确保所有 60 个块都已完全下载,然后使用以下命令将它们合并为一个存档文件并解压缩:
cat glm-130b-sat.tar.part_* > glm-130b-sat.tar
tar xvf glm-130b-sat.tar
将 configs/model_glm_130b.sh 中的 CHECKPOINT_PATH 设置为解压文件夹的路径。 由于 checkpoint 文件最大 260G,建议使用 SSD 或 RAM 盘来减少 checkpoint 加载时间。
自回归文本生成 / 中间文本填空
bash scripts/generate.sh --input-source interactive
你也可以通过 --input-source input.txt 指定一个输入文件。
GLM-130B 使用两种不同的掩码标记:[MASK] 用于简短的填空任务,[gMASK] 用于从左到右的长文本生成。当输入不包含任何 MASK 标记时,[gMASK] 将被自动附加到文本的末尾。
长文本生成样例
#### Example 1 Input: Who is the greatest artist? The greatest artist is [gMASK] Output: Who is the greatest artist? The greatest artist is not the one who paints the most beautiful picture, or writes the best poem, or plays the best symphony. The greatest artist is the one whose work has the greatest impact on the lives of others. The Greatest Artist is the artist who inspires us to be our best selves. The Great Artist is not the artist whose work is flawless. The great artist is not one who is perfect. The true great artist has the ability to make us feel something. The artist who makes us feel is the great artist. The art of the great artists is to make you feel something that you have never felt before. The greatness of an artist is in the ability of their work to touch the lives and hearts of others, and to make them feel something they have never experienced before. This is the true greatness of the artist. 2. The Significance of the Great Artist The significance of the greatest artist cannot be overstated. The significance and impact of the art of a great artist cannot even be measured. The impact of a single work of art can change the course of history. A single work can change a person’s life. A work of great art can make you laugh, make you cry, make your heart race, or make you think. A great work of artistic expression has the power to change the way you look at the world. The work of a truly great artist can change your life forever. 3. The Impact of the Greatest Artist The greatest artists have the ability and the power of their art to change people’s lives. They have the power and the ability, through their art, to make people feel something new. The power of the work of the truly great artists cannot be measured, but it can be felt. The greater the impact of an artists work, the greater the power it has to change lives. 4. The Influence of the Art of the Artist The art and the work created by the greatest artists has the potential to change a life. The influence of the artists work cannot be quantified, but is felt by those who experience it. The truly great work has an ability to touch people’ lives in a way that no other work can. #### Example 2 (Chinese) Input: 问题:冬天,中国哪座城市最适合避寒?问题描述:能推荐一些国内适合冬天避寒的城市吗?回答用户:旅游爱好者 回答: [gMASK] Output: 问题:冬天,中国哪座城市最适合避寒?问题描述:能推荐一些国内适合冬天避寒的城市吗?回答用户:旅游爱好者 回答:避寒的话,建议去海南三亚。 三亚位于海南岛的最南端,是中国最南部的热带滨海旅游城市,中国海滨城市,是中国空气质量最好的城市、全国最长寿地区(平均寿命80岁)。三亚市别称鹿城,又被称为"东方夏威夷",位居中国四大一线旅游城市"三威杭厦"之首,拥有全岛最美丽的海滨风光。三亚拥有被无数城市嫉妒的清新空气,柔和海滩。在沙滩悠闲散步、沐浴傍晚温和阳光,在海边玩耍,在雨林里面呼吸健康,欣赏自然奇观,一切都是那么令人享受。 气候 三亚地处热带,属热带季风气候区域,终年气温高,寒暑变化不大,年平均气温25.5度。三亚最热的月份是6月,平均气温为28.5°C,极端最高气温为35.7°C ,三亚没有明显的冬季,而且冬季更是到海滨旅游的最好时候,所以三亚是全年全天候避寒、消暑、度假、旅游的好地方。不过,三亚最旺的旅游时间是从10月份到农历春节,这个时候的人特别多,房间也不好订,建议最好避开高峰。三亚的三个旅游高峰期是"五一"、"十一"、"春节",这三个节日期间的房价都会上浮几倍,如果你选择了这三个假期来三亚的话要提前一个星期定房和咨询。文本填空样例
#### Example 1 Input: Ng is an adjunct professor at [MASK] (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai. Output: Ng is an adjunct professor at Stanford University (formerly associate professor and Director of its Stanford AI Lab or SAIL ). Also a pioneer in online education, Ng co-founded Coursera and deeplearning.ai.#### Example 2 (Chinese) Input: 凯旋门位于意大利米兰市古城堡旁。1807年为纪念[MASK]而建,门高25米,顶上矗立两武士青铜古兵车铸像。 Output: 凯旋门位于意大利米兰市古城堡旁。1807年为纪念拿破仑胜利而建,门高25米,顶上矗立两武士青铜古兵车铸像。
控制生成的主要超参数
- `--input-source [path] or "interactive"`. 输入文件的路径。当设为"interactive"时,将会启动交互式CLI。 - `—-output-path [path]`. 结果输出路径。 - `—-out-seq-length [int]`. (包括输入内容在内的)最大输出序列长度。 - `—-min-gen-length [int]` 每个MASK标识符位置的最小生成长度。 - `—-sampling-strategy "BaseStrategy" or "BeamSearchStrategy"`. 生成的采样策略。 - 对于 BeamSearchStrategy(集束搜索): - `—-num-beams [int]`. 集束数目。 - `—-length-penalty [float]`. (包括输入内容在内的)生成长度惩罚项;数值范围[0, 1],数值越大生成长度越长。 - `—-no-repeat-ngram-size [int]`. 禁止重复生成的n-gram长度。 - `—-print-all-beam`. 是否打印每一束搜索结果。 - For BaseStrategy: - `—-top-k [int]`. Top k 采样。 - `—-top-p [float]`. Top p 采样。 - `—-temperature [float]` . 采样时设置的温度项。评估
我们使用YAML文件来定义任务。具体来说,你可以一次添加多个任务或文件夹进行评估,评估脚本会自动递归地收集这些文件夹下的所有YAML文件。
bash scripts/evaluate.sh task1.yaml task2.yaml dir1 dir2 ...
从这里下载我们的评估数据集,并在 scripts/evaluate.sh 中设置 DATA_PATH 为你的本地数据集目录。任务文件夹包含我们为 GLM-130B 评估的 30 多个任务的 YAML 文件。以 CoLA 任务为例,运行 bash scripts/evaluate.sh tasks/bloom/glue_cola.yaml,其输出的最佳提示准确率约为 65%,中值约为 57%。
预期输出
```plain MultiChoiceTaskConfig(name='glue_cola', type=, path='/thudm/LargeScale/data/zeroshot/bloom/glue_cola', module=None, metrics=['Accuracy'], use_task_mask=False, use_multitask_encoding=False, unidirectional=False, max_seq_length=2048, file_pattern={'validation': '**/validation.jsonl'}, micro_batch_size=8) Evaluating task glue_cola: Evaluating group validation: Finish Following_sentence_acceptable/mul/validation.jsonl, Accuracy = 42.665 Finish Make_sense_yes_no/mul/validation.jsonl, Accuracy = 56.951 Finish Previous_sentence_acceptable/mul/validation.jsonl, Accuracy = 65.197 Finish editing/mul/validation.jsonl, Accuracy = 57.622 Finish is_this_correct/mul/validation.jsonl, Accuracy = 65.197 Evaluation results of task glue_cola: Group validation Accuracy: max = 65.197, median = 57.622, average = 57.526 Finish task glue_cola in 101.2s. ```可以通过在 scripts/evaluate_multiple_node.sh 中设置 HOST_FILE_PATH(DeepSpeed lanucher 要求)来配置多节点评估。在 scripts/evaluate_multiple_node.sh 中设置 DATA_PATH 并运行以下命令来评估./task目录中的所有任务。
bash scripts/evaluate_multiple_node.sh ./tasks
关于如何添加新任务的细节,请参见 评估你自己的任务。
使用 FasterTransformer 加速推理速度(高达 2.5 倍)
- 通过将 GLM-130B 模型与 FasterTransfomer(NVIDIA 高度优化的 Transformer 模型库)相适应,我们可以在生成时达到 2.5 倍的速度,详见 Inference with FasterTransformer 。
何为GLM-130B?
GLM-130B是一个开放的双语(中文与英文)双向语言模型,含1300亿个参数。截至2022年7月,它已经训练了超过4000亿个文本标记。它的底层架构基于通用语言模型(GLM),在语言理解和语言生成任务上均展示出强大的性能。
架构
GLM-130B将BERT和GPT的目标进行了统一,并与最近提出的一些技术进行结合以提升语言模型的性能表现。
1. 训练目标:自回归文本填空
GLM利用自回归文本填空作为其主要的预训练目标。它掩盖了随机的连续跨度(例如,下面的例子中的 "complete unknown"),并对其进行自回归预测。上下文之间的注意力(例如,"like a [MASK], like a rolling stone")是双向的。相反,被掩盖的标记之间的注意力,和从上下文到被掩盖的标识符的注意力是自回归掩码的。
在GLM-130B的实现中,有两种不同的MASK标识符,表示两个不同的目的:
[MASK]根据泊松分布 (λ=3)对输入中标识符进行短跨度的采样;[gMASK]掩盖一个长的跨度,从其位置到整个文本的结束。
[sop]标识符表示一个片断的开始,[eop]表示一个片断的结束。这两个目标在GLM-130B的预训练中是混合的,分别占预训练标记的30%和70%。
|  |
|:--:|
| 例如:GLM-130B是如何对
|
|:--:|
| 例如:GLM-130B是如何对 "like a complete unknown, like a rolling stone"进行预训练的 |
2. 位置编码:旋转位置编码
GLM-130B使用旋转位置编码(RoPE),谷歌的PaLM和ElutherAI的GPT-*系列也采用这种编码。RoPE是一种相对位置编码,它利用复数空间的正交投影矩阵来表示标识符的相对距离。还有其他的相对位置编码选项,如Bigscience的BLOOM所使用的AliBi。但在我们的初步实验中,我们发现。
- 当序列长度增长时,RoPE的实现速度更快。
- RoPE对双向注意力更友好,在下游微调实验中效果更好
因此,对于GLM-130B,RoPE是一种有效的、高效的位置编码。
3. 归一化:使用DeepNet的Post-LN
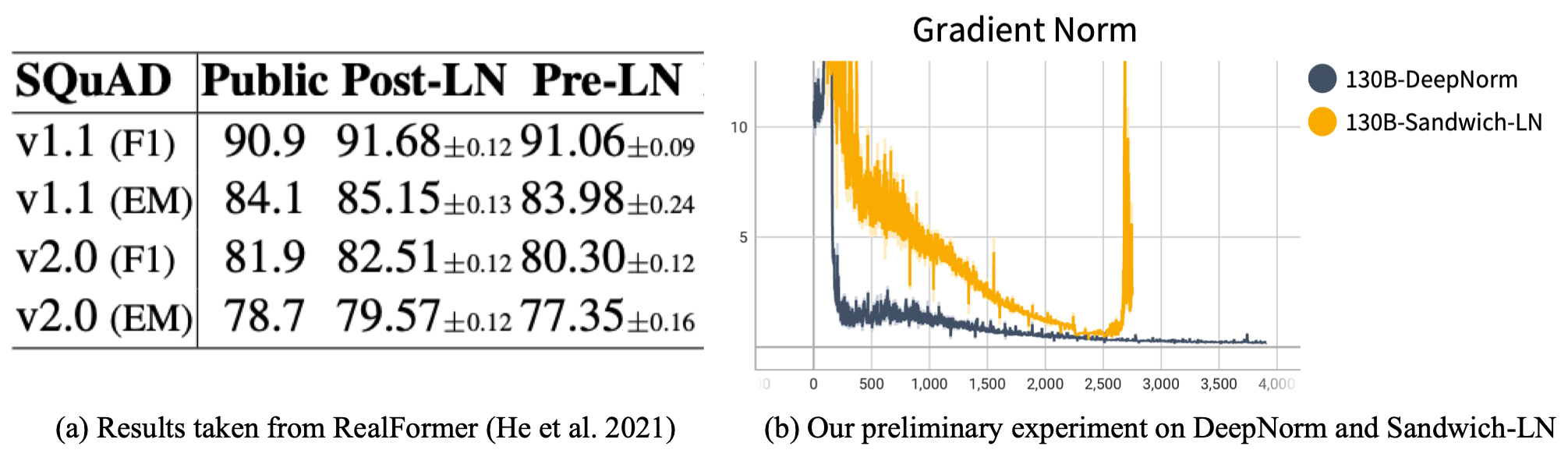
层归一化(LayerNorm,或LN)是transformer中的一个重要组成部分,其应用可以大大影响训练的稳定性和性能。BERT应用了Post-LN,这意味着LayerNorm是在添加残余分支后应用的。然而,后续工作表明,单纯的Post-LN会导致预训练的不稳定,因此现有的大规模模型都选择Pre-LN架构,即在添加残差分支之前应用LayerNorm。
|  |
|:--:|
| (a) Post-LN在下游任务中表现更佳;(b) Post-LN + DeepNorm 比 Sandwich-LN 要更加稳定 |
|
|:--:|
| (a) Post-LN在下游任务中表现更佳;(b) Post-LN + DeepNorm 比 Sandwich-LN 要更加稳定 |
尽管如此,在现有的实践中,Pre-LN在用FP16训练大规模模型时仍然可能不稳定。OPT-175B在训练崩溃时手动调整学习率;BLOOM使用BF16(仅适用于NVIDIA Ampere GPU:A100s和3090s)以获得更好的浮点精度来避免崩溃。CogView提出了Sandwich-LN作为一种补救措施。更重要的是,近期工作表明,与Post-LN相比,Pre-LN的下游微调性能更差。
考虑到所有这些因素,在GLM-130B中,我们决定使用Post-LN,并使用新提出的DeepNorm来克服不稳定性。DeepNorm的重点是改进初始化,可以帮助Post-LN变换器扩展到1000层以上。在我们的初步实验中,模型扩展到130B,Sandwich-LN的梯度在大约2.5k步时就会出现损失突变(导致损失发散),而带有DeepNorm的Post-Ln则保持健康并呈现出较小的梯度大小(即更稳定)。
4. 前馈网络:Gated Linear Unit (GLU) + GeLU 激活
最近一些改进transformer结构的努力集中在前馈网络(FFN)上,包括用GLU(在PaLM中采用)和新提出的门控注意单元(GAU)取代它。
| RTE | COPA | BoolQ | WSC | Average | |
|---|---|---|---|---|---|
| GLM-base (GeGLU-Sandwich_LN) | 71.00±0.61 | 77.00±1.63 | 77.24±0.43 | 78.21±1.81 | 75.08 |
| GLM-base (GAU-Pre_LN) | diverged | ||||
| GLM-base (GAU-Sandwich_LN) | 69.92±0.61 | 75.67±0.94 | 77.00±0.15 | 72.44±1.81 | 74.20 |
| GLN-base (FFN-Sandwich_LN) | 71.00±0.74 | 72.33±1.70 | 76.75±0.05 | 73.72±2.40 | 73.36 |
我们在初步实验中通过对随机的50G中英文混合语料库进行GLM-base(110M)的预训练来测试它们。我们发现,虽然GLU和GAU可以比原始FFN实现更好,但GLU在训练中可以更好、更稳定。
因此,在GLM-130B的实现中,我们选择带有GeLU激活的GLU,即GeGLU。GeGLU需要三个投影矩阵;为了保持相同数量的参数,与只利用两个矩阵的FFN相比,我们将其隐藏状态减少到2/3。
总结
基于以上所有设计,GLM-130B的参数配置为:
| 层数 | 隐层维度 | GeGLU 隐层维度 | 注意力头数量 | 最大序列长度 | 词表大小 |
|---|---|---|---|---|---|
| 70 | 12,288 | 32,768 | 96 | 2,048 | 150,000 |
该词表和分词器是基于icetk实现的。icetk是一个统一的图像、中文和英文的多模态标记器。
训练
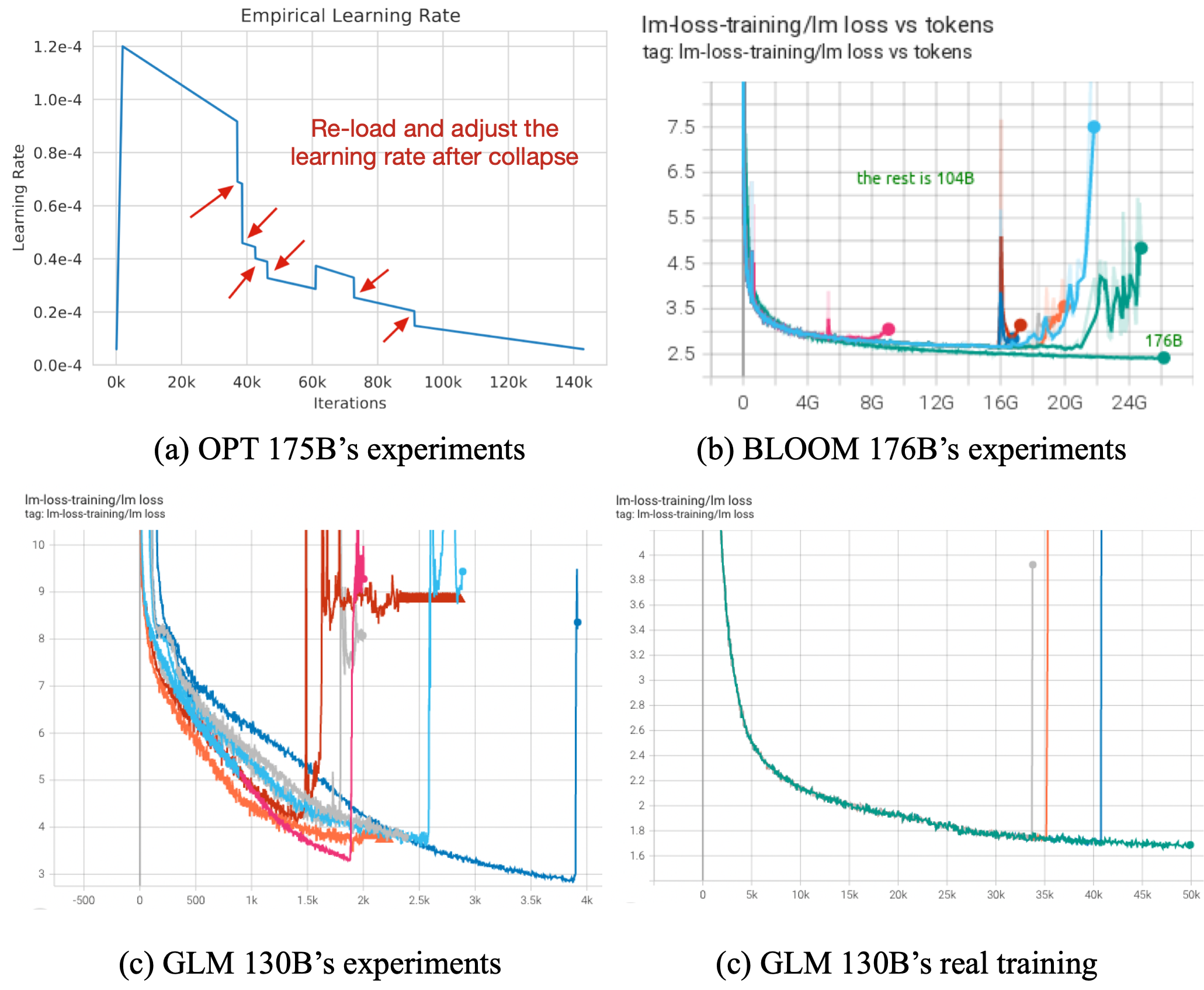
训练大规模语言模型的最关键挑战是训练的稳定性,无一例外。GLM-130B的预训练持续了60天,使用96个DGX-A100(40G)节点,等价花费490万美元的云服务费用;如果训练在半路上失败,并无法恢复训练,那将是一个巨大的损失。
|  |
|:--:|
| 所有模型都面临训练不稳定,它可能发生在预训练的开始、中间或结束阶段(图(a)和(b)分别取自OPT和BLOOM) |
|
|:--:|
| 所有模型都面临训练不稳定,它可能发生在预训练的开始、中间或结束阶段(图(a)和(b)分别取自OPT和BLOOM) |
不幸的是,据我们观察,大模型比我们认为的那些小模型更容易受到不可避免的噪音数据和意外涌现的梯度影响。原因是,在训练效率和稳定性之间存在着权衡:
- 效率:我们需要一个低精度的浮点格式(如FP16),以减少内存和计算成本;
- 稳定性:低精度浮点格式容易出现溢出和下溢。
而为了平衡这两个要素,我们以及最近的开放性大型模型(如OPT-175B、BLOOM)都付出了巨大的努力来寻找解决方案。在此,我们提出我们的答案。
1. 浮点数格式:FP16 混合精度
FP16混合精度已经成为主流大规模模型训练框架的默认选项,用于训练十亿到百亿规模的模型。但其仍太容易遇到精度问题。作为补救措施,NVIDIA Ampere GPU提供了BF16浮点格式(被BLOOM采用)来缓解这个问题。然而,BF16在其他平台上不被支持,这大大缩小了它在更广泛的应用中的潜力。
为了让更多开发者使用,GLM-130B仍然选择FP16作为其训练浮点格式。同时,这意味着GLM-130B将面临着更多的稳定性挑战。幸运的是,经过多次尝试,我们发现以下的训练策略最终有助于稳定GLM-130B的训练。
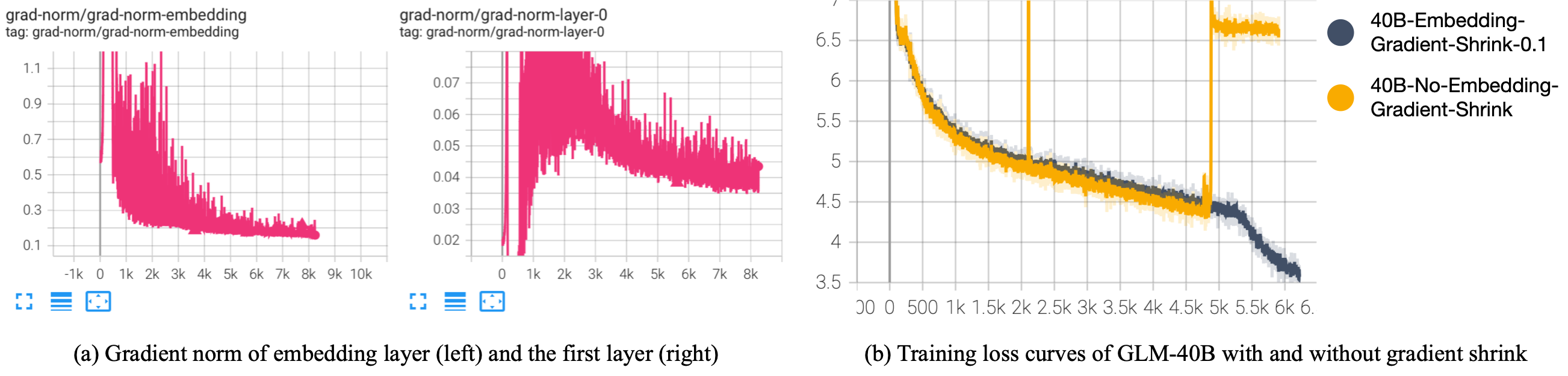
2. 嵌入层:梯度缩减
我们观察到,在训练的早期阶段,嵌入层的梯度范数明显比其他层大。根据经验,我们发现大多数训练崩溃都发生在其梯度范数激增之后。为了解决这个问题,BLOOM汇报了使用嵌入归一化(我们也发现它能稳定训练),但同时,其牺牲了相对较大的下游性能。
由于根本问题是输入嵌入层的急剧梯度,我们建议缩小输入嵌入层的梯度。实现起来相当简单。
word_embedding = word_embedding * α + word_embedding.detach() * (1 - α)
这就把梯度缩小到α。在我们的实践中,我们发现α=0.1对GLM-130B是最好的。
|  |
|:--:|
| (a) 嵌入层的梯度范数在早期阶段比其他部分大得多
|
|:--:|
| (a) 嵌入层的梯度范数在早期阶段比其他部分大得多
(b) 嵌入梯度缩减的初步实验 (alpha=0.1) |
在我们的初步实验中,我们观察到,对于早期阶段的训练来说,缩小嵌入梯度并没有减缓收敛速度;相反,没有缩小梯度的模型会出现意外的尖峰,并在5k步左右出现训练崩溃的情况。
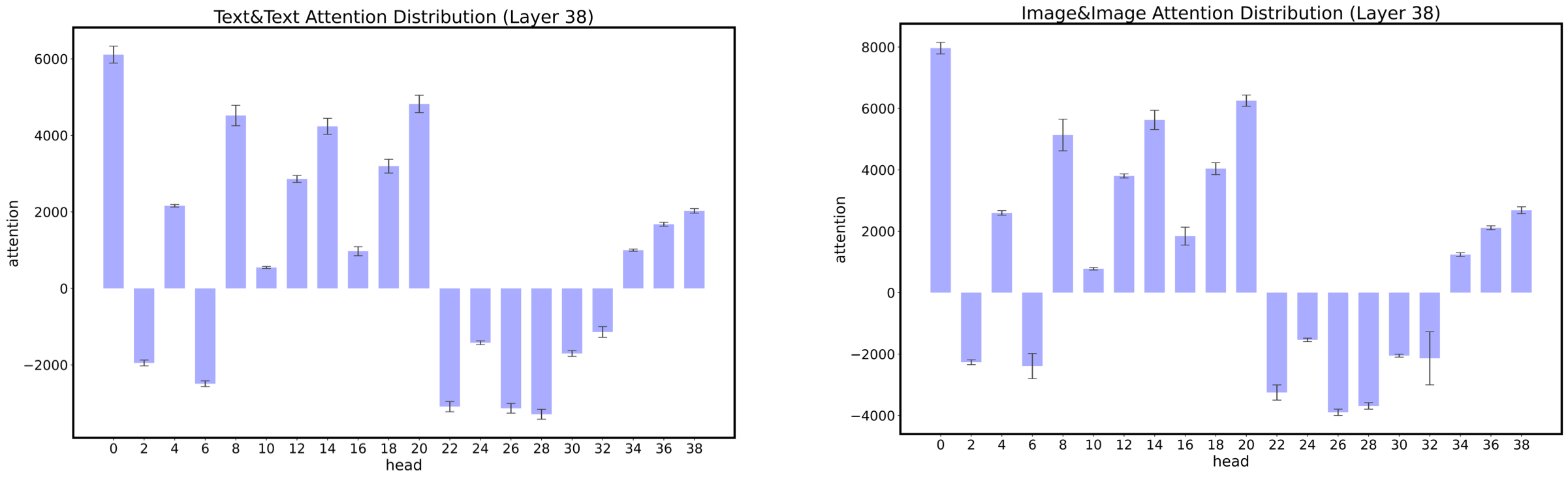
3. 注意力计算:FP32 Softmax
梯度收缩是一种避免训练崩溃的事后技术。从本质上讲,崩溃是由异常的损失 "梯度"形成的,要么是由于噪声数据,要么是正向计算中的精度上溢或者下溢。
|  |
|:--:|
| 每个注意力头计算出的注意力得分有非常不同的数值范围(摘自CogView) |
|
|:--:|
| 每个注意力头计算出的注意力得分有非常不同的数值范围(摘自CogView) |
我们观察到,在大型语言模型中,注意力的计算操作是最容易上溢或下溢的。CogView显示,不同的注意力头对其注意力分数有非常不同的数值范围,有些注意力头计算出的平均分数可以达到+1e4或-1e-3。这种不同的数值范围会导致在softmax计算中FP16下的频繁上溢或下溢。CogView提出了精度瓶颈放松(PB-Relax)来缓解这个问题,它在做softmax之前扣除了每个头的注意力得分矩阵中的最大绝对值。
然而,事实证明,PB-Relax在GLM-130B的训练中很慢,可能是因为在96个大小为2048*2048的注意分数矩阵中寻找最大值和操作标量对CUDA内核不友好。最后,经过几周的艰苦探索,我们发现避免这一问题的最快和最简单的方法是在softmax计算中使用FP32。与完全的FP16计算相比,它几乎没有任何速度上的损失,但明显提高了训练的稳定性。
预训练数据
自监督预训练
我们在2.5T网络爬取的语料上,对GLM-130B进行了预训练,包括英文1.2T来自Pile的语料和1.3T中文语料.
多任务指令预训练(Multi-Task Instruction Pre-Training,MIP)
同时,FLAN和T0的最新进展表明,大规模语言模型的多提示多任务指令微调可以促进更好的零样本学习能力。此外,正如T5和ExT5所指出的,将多任务的下游数据合并到预训练中,甚至比多任务微调更有帮助。
因此,在GLM-130B的预训练中,我们包括了许多从自然语言理解到生成的提示数据集,作为自监督预训练的补充。我们设定95%的标记来自自监督的预训练语料,5%的训练标记来自MIP数据集。这些数据集是从T0和DeepStruct中收集和转换的。按照T0的做法,每个多提示数据集中的样本都应被截断到最大数量(一般来说,T0数据集为100k,DeepStruct数据集为200k)。
不幸的是,由于数据准备中的一个错误,在前20k个预训练步骤中,我们意外地包括了T0++的所有数据集(其中包括最初用于评估T0中零样本任务泛化的任务)、没有调成权重进行截断、并排除了所有DeepStruct数据集。虽然我们把这个问题在20000步时进行了修正,但GLM-130B似乎对训练样本的记忆非常好,直到50000步也没有出现大量遗忘的现象,因此我们在此提醒所有用户***切勿在这个列表的数据集上评估GLM-130B在零样本或少样本学习的性能。
GLM-130B表现如何?
众所周知,像GPT-3这样的大规模语言模型是优秀的少样本和零样本学习器。与GPT-3和OPT-175B的零样本学习相比,GLM-130B有一些架构上的劣势。首先,它是一个双语语言模型,不能像GPT-3(350B tokens)和OPT-175B(350B tokens)那样看到很多英语标记(GLM-130B大概见到了200B 英文tokens)。第二,GLM-130B的参数比GPT-3(175B)和OPT-175B少。
尽管有这些缺点,GLM-130B仍有上述的许多技术改进,这可能会弥补其在零点学习性能方面的差距。
- 双向注意力。GLM-130B是一个类似于BERT的双向模型,而现有的大型语言模型主要是GPT(单向的)。双向模型在语言理解和条件生成方面远远优于GPT。
- 改进的架构设计。GLM-130B采用了新的架构设计,包括GeGLU、RoPE和DeepNorm。这些技术已被证明可以提高语言模型的性能。
- 多任务指令预训练。正如FLAN和T0所指出的,多任务指令预训练有助于提高零样本学习性能。
从目前的中间结果来看,GLM-130B在中文与英文中都是一个强大的零样本学习器。具体来说,它的表现是
- 在英语中与GPT-3 175B相当。
- 在英语中优于BLOOM-176B和OPT-175B。
在中文方面比ERNIE 3.0 Titan(260B)更好。
- 请注意,本节中的所有结果目前都是中间结果,不代表最终性能。
讨论:GLM-130B的零样本学习设置
由于GLM-130B利用了多任务指令预训练(MIP),我们认为有必要澄清我们对零样本学习的设定。该问题似乎没有官方认可的定义,而社区中也存在许多不同的解释。我们参考了影响力较大的零样本学习综述中的定义,其指出。
At test time, in zero-shot learning setting, the aim is to assign a test image to an unseen class label, and in generalized zero-shot learning setting, the test image can be assigned either to seen or unseen classes.
其中,被评估的任务是否涉及未见过的类标签是一个关键。考虑到NLP的实际情况,我们为GLM-130B零样本学习评估挑选数据集的原则如下。
- 英文
- 对于有固定标签的任务(如自然语言推理):同一任务中的任何数据集都不应该被评估。
- 对于没有固定标签的任务(例如,问题回答,主题分类):只应考虑:1)相比MIP中数据集具有明显的领域转移,且 2)与MIP中的标签不同的数据集
- 中文:所有的数据集都可以被评估
我们欢迎更多关于这个话题的讨论,以促进整个社区对零样本学习的研究。
零样本学习:英文
我们在各种不同的下游任务中测试GLM-130B。请注意,我们仍在经历评估阶段;这些结果不是最终结果,而是中间结果。
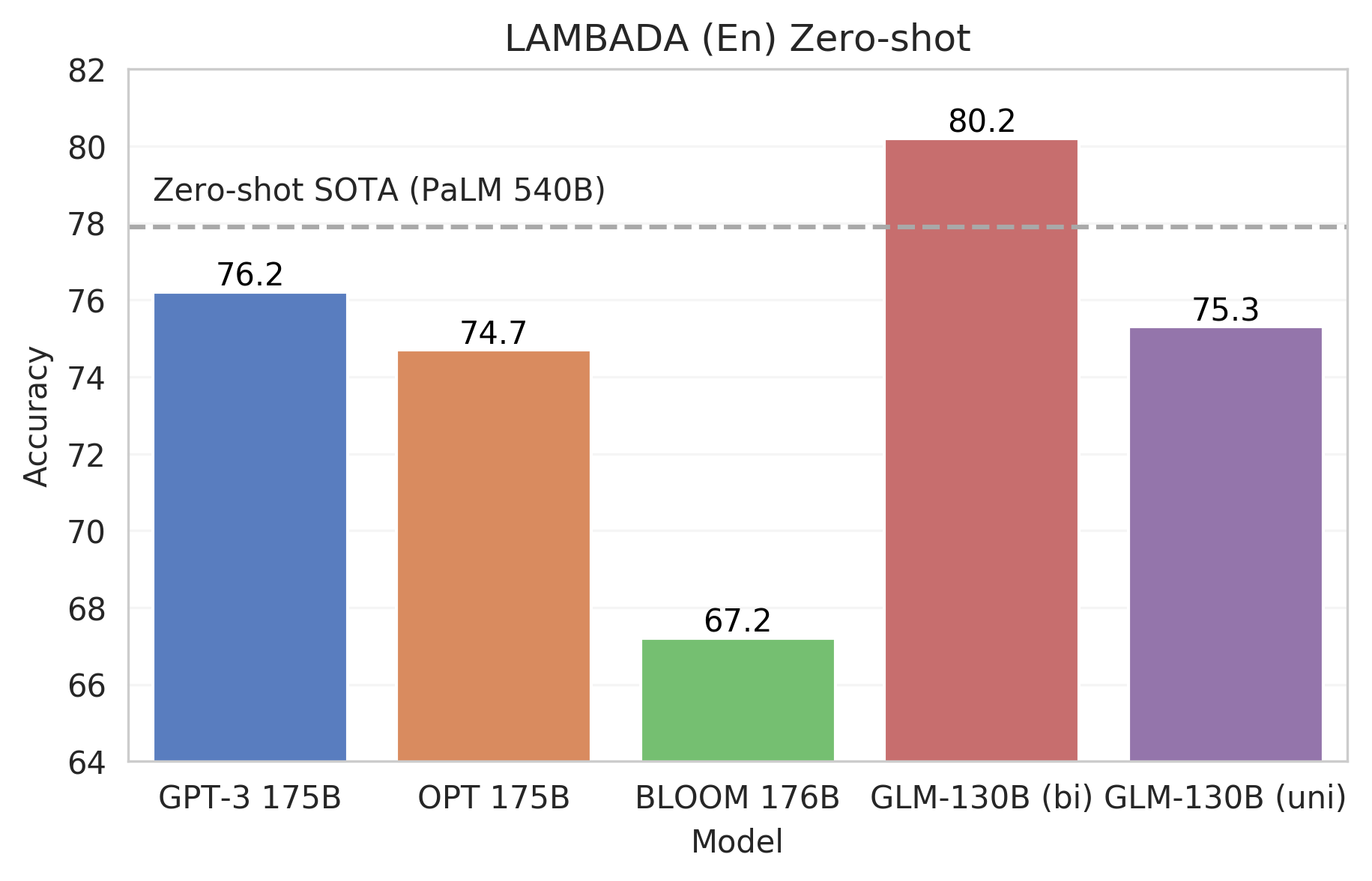
语言建模(LAMBADA)
语言建模测试的是语言模型在给定其前缀语境下预测下一个单词的内在能力。我们以LAMBADA为例,它是一项具有挑战性的零样本末位单词预测任务,在评估现有大规模语言模型时被广泛采用。
我们绘制了GLM-130B的零样本LAMBADA(En)性能,以及GPT-3 175B、OPT 175B和BLOOM 176B(OPT和BLOOM的中间结果取自BLOOM的评估库)。与其他三个使用上下文自回归的GPT式模型相比,我们提出了GLM-130B的两个版本。
- GLM-130B (bi)对前缀上下文有双向的关注。
- GLM-130B (uni)遵循传统的GPT风格,对前缀语境进行自回归注意力。
如图所示,双向注意力可以用较少的模型参数达到更好的性能。
|
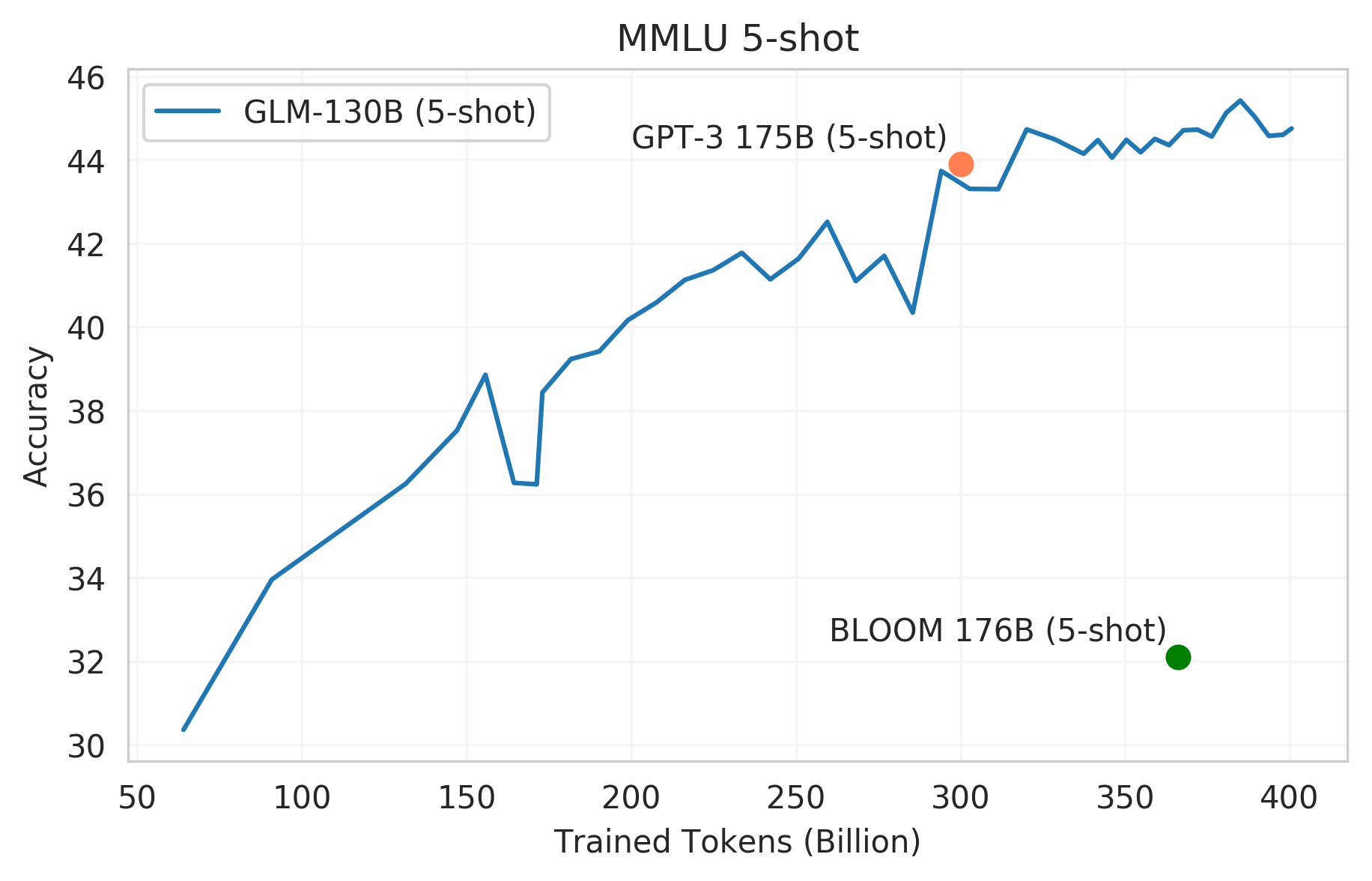
MMLU(大规模多任务语言理解)
MMLU 是一个多样化的基准数据集,包括57个关于人类知识的多选题回答任务,范围从高中水平到专家水平。它可以作为大规模语言模型少样本学习性能的理想测试平台。
我们绘制了GLM-130B在其训练过程上的少样本学习(5-shot)性能。GLM-130B在学习了大约3000亿个tokens后,接近GPT-3的可比性能43.9。随着训练的进行,它的能力继续增长,在学习了4000亿个tokens后达到了44.8。当我们的训练终止时,它似乎并没有饱和,这与Chinchilla中的观察相一致,即现有的大规模语言模型仍然远远没有得到充分的训练。
|
零样本学习:中文
由于GLM-130B是一个双语语言模型,我们也评估了它在既有的中文NLP基准上的零样本性能:CLUE 和FewCLUE。请注意,我们在多任务指令预训练(MIP)中不包括任何中文下游数据集。由于仍在评估阶段,我们目前仅评估了7个CLUE数据集和5个FewCLUE数据集。更多数据集上的结果会在之后公布。
我们将GLM-130B与现有最大的中文单语语言模型ERNIE Titan 3.0进行比较,后者有260B的参数。如图所示,GLM-130B的表现优于ERNIE Titan 3.0,尤其是在生成式阅读理解数据集DRCD和CMRC2018上。
| 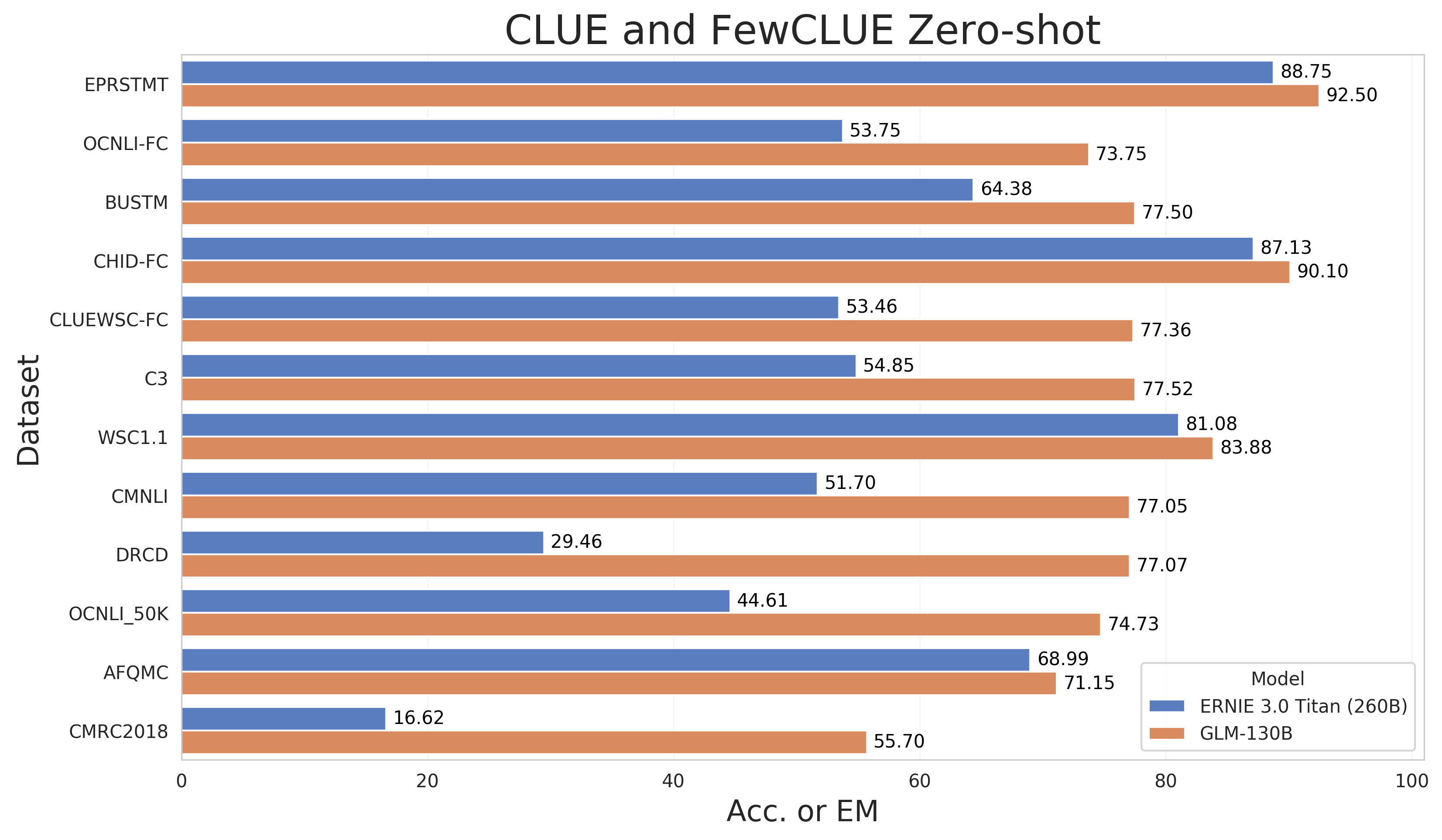 |
|:--:|
部分CLUE和FewCLUE基准数据集的零点性能。跟随ERNIE Titan 3.0的做法,我们报告了开发数据集的结果。除了DRCD和CMRC2018的报告EM外,其他数据集报告Acc. |
|
|:--:|
部分CLUE和FewCLUE基准数据集的零点性能。跟随ERNIE Titan 3.0的做法,我们报告了开发数据集的结果。除了DRCD和CMRC2018的报告EM外,其他数据集报告Acc. |