|
|
@@ -0,0 +1,196 @@
|
|
|
+# SeamlessM4T
|
|
|
+SeamlessM4T is our foundational all-in-one **M**assively **M**ultilingual and **M**ultimodal **M**achine **T**ranslation model delivering high-quality translation for speech and text in nearly 100 languages.
|
|
|
+
|
|
|
+SeamlessM4T models support:
|
|
|
+- :microphone: 101 languages for speech input.
|
|
|
+- :speech_balloon: 96 Languages for text input/output.
|
|
|
+- :speaker: 35 languages for speech output.
|
|
|
+
|
|
|
+This unified model enables multiple tasks without relying on multiple separate models:
|
|
|
+- Speech-to-speech translation (S2ST)
|
|
|
+- Speech-to-text translation (S2TT)
|
|
|
+- Text-to-speech translation (T2ST)
|
|
|
+- Text-to-text translation (T2TT)
|
|
|
+- Automatic speech recognition (ASR).
|
|
|
+
|
|
|
+
|
|
|
+## SeamlessM4T v1
|
|
|
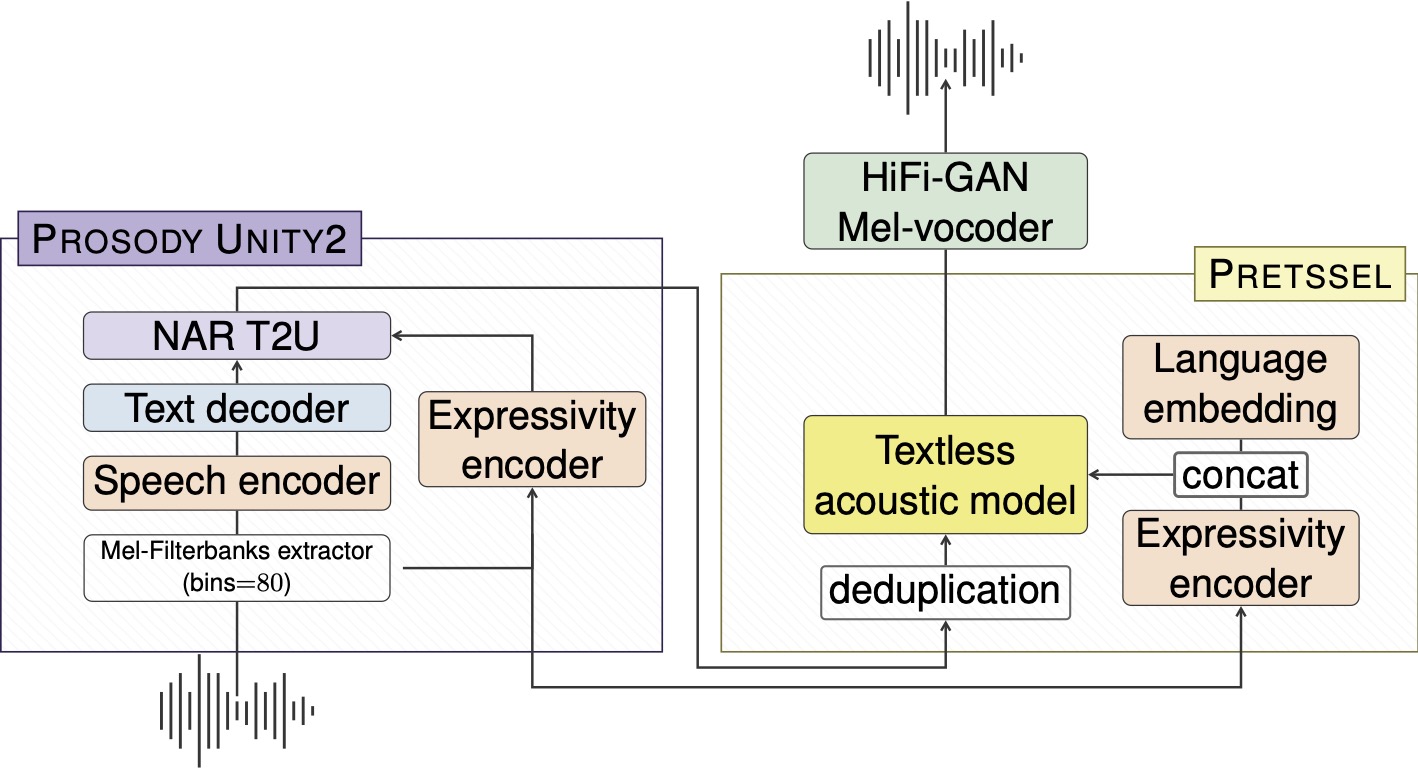
+The v1 version of SeamlessM4T is a multitask adaptation of the *UnitY* architecture [(Inaguma et al., 2023)](https://aclanthology.org/2023.acl-long.872/).
|
|
|
+*UnitY* is a two-pass direct S2ST architecture which first generates textual representations and subsequently predicts discrete acoustic units.
|
|
|
+
|
|
|
+
|
|
|
+## SeamlessM4T v2
|
|
|
+The v2 version of SeamlessM4T is a multitask adaptation of our novel *UnitY2* architecture.
|
|
|
+*Unity2* with its hierarchical character-to-unit upsampling and non-autoregressive text-to-unit decoding considerably improves over SeamlessM4T v1 in quality and inference speed.
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+
|
|
|
+## SeamlessM4T models
|
|
|
+| Model Name | #params | checkpoint | metrics |
|
|
|
+| ------------------ | ------- | --------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------ |
|
|
|
+| SeamlessM4T-Large v2 | 2.3B | [🤗 Model card](https://huggingface.co/facebook/??) - [checkpoint](?) | [metrics](https://dl.fbaipublicfiles.com/seamless/metrics/seamlessM4T_large_v2.zip) |
|
|
|
+| SeamlessM4T-Large (v1) | 2.3B | [🤗 Model card](https://huggingface.co/facebook/seamless-m4t-large) - [checkpoint](https://huggingface.co/facebook/seamless-m4t-large/resolve/main/multitask_unity_large.pt) | [metrics](https://dl.fbaipublicfiles.com/seamless/metrics/seamlessM4T_large.zip) |
|
|
|
+| SeamlessM4T-Medium (v1) | 1.2B | [🤗 Model card](https://huggingface.co/facebook/seamless-m4t-medium) - [checkpoint](https://huggingface.co/facebook/seamless-m4t-medium/resolve/main/multitask_unity_medium.pt) | [metrics](https://dl.fbaipublicfiles.com/seamless/metrics/seamlessM4T_medium.zip) |
|
|
|
+
|
|
|
+We provide the extensive evaluation results of seamlessM4T-Large and SeamlessM4T-Medium reported in the paper (as averages) in the `metrics` files above.
|
|
|
+
|
|
|
+The evaluation data ids for FLEURS, CoVoST2 and CVSS-C can be found [here](https://dl.fbaipublicfiles.com/seamless/metrics/evaluation_data_ids.zip)
|
|
|
+
|
|
|
+
|
|
|
+## Evaluating SeamlessM4T models
|
|
|
+To reproduce our results, or to evaluate using the same metrics over your own test sets, please check out the [Evaluation README here](../../src/seamless_communication/cli/m4t/evaluate/README.md).
|
|
|
+
|
|
|
+
|
|
|
+## Finetuning SeamlessM4T models
|
|
|
+Please check out the [Finetuning README here](../../src/seamless_communication/cli/m4t/finetune/README.md).
|
|
|
+
|
|
|
+## Supported Languages:
|
|
|
+
|
|
|
+Listed below, are the languages supported by SeamlessM4T-large (v1/v2).
|
|
|
+The `source` column specifies whether a language is supported as source speech (`Sp`) and/or source text (`Tx`).
|
|
|
+The `target` column specifies whether a language is supported as target speech (`Sp`) and/or target text (`Tx`).
|
|
|
+
|
|
|
+
|
|
|
+| code | language | script | Source | Target |
|
|
|
+| ---- | ---------------------- | ---------- | ------ | ------ |
|
|
|
+| afr | Afrikaans | Latn | Sp, Tx | Tx |
|
|
|
+| amh | Amharic | Ethi | Sp, Tx | Tx |
|
|
|
+| arb | Modern Standard Arabic | Arab | Sp, Tx | Sp, Tx |
|
|
|
+| ary | Moroccan Arabic | Arab | Sp, Tx | Tx |
|
|
|
+| arz | Egyptian Arabic | Arab | Sp, Tx | Tx |
|
|
|
+| asm | Assamese | Beng | Sp, Tx | Tx |
|
|
|
+| ast | Asturian | Latn | Sp | \-- |
|
|
|
+| azj | North Azerbaijani | Latn | Sp, Tx | Tx |
|
|
|
+| bel | Belarusian | Cyrl | Sp, Tx | Tx |
|
|
|
+| ben | Bengali | Beng | Sp, Tx | Sp, Tx |
|
|
|
+| bos | Bosnian | Latn | Sp, Tx | Tx |
|
|
|
+| bul | Bulgarian | Cyrl | Sp, Tx | Tx |
|
|
|
+| cat | Catalan | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| ceb | Cebuano | Latn | Sp, Tx | Tx |
|
|
|
+| ces | Czech | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| ckb | Central Kurdish | Arab | Sp, Tx | Tx |
|
|
|
+| cmn | Mandarin Chinese | Hans | Sp, Tx | Sp, Tx |
|
|
|
+| cmn_Hant | Mandarin Chinese | Hant | Sp, Tx | Sp, Tx |
|
|
|
+| cym | Welsh | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| dan | Danish | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| deu | German | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| ell | Greek | Grek | Sp, Tx | Tx |
|
|
|
+| eng | English | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| est | Estonian | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| eus | Basque | Latn | Sp, Tx | Tx |
|
|
|
+| fin | Finnish | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| fra | French | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| fuv | Nigerian Fulfulde | Latn | Sp, Tx | Tx |
|
|
|
+| gaz | West Central Oromo | Latn | Sp, Tx | Tx |
|
|
|
+| gle | Irish | Latn | Sp, Tx | Tx |
|
|
|
+| glg | Galician | Latn | Sp, Tx | Tx |
|
|
|
+| guj | Gujarati | Gujr | Sp, Tx | Tx |
|
|
|
+| heb | Hebrew | Hebr | Sp, Tx | Tx |
|
|
|
+| hin | Hindi | Deva | Sp, Tx | Sp, Tx |
|
|
|
+| hrv | Croatian | Latn | Sp, Tx | Tx |
|
|
|
+| hun | Hungarian | Latn | Sp, Tx | Tx |
|
|
|
+| hye | Armenian | Armn | Sp, Tx | Tx |
|
|
|
+| ibo | Igbo | Latn | Sp, Tx | Tx |
|
|
|
+| ind | Indonesian | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| isl | Icelandic | Latn | Sp, Tx | Tx |
|
|
|
+| ita | Italian | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| jav | Javanese | Latn | Sp, Tx | Tx |
|
|
|
+| jpn | Japanese | Jpan | Sp, Tx | Sp, Tx |
|
|
|
+| kam | Kamba | Latn | Sp | \-- |
|
|
|
+| kan | Kannada | Knda | Sp, Tx | Tx |
|
|
|
+| kat | Georgian | Geor | Sp, Tx | Tx |
|
|
|
+| kaz | Kazakh | Cyrl | Sp, Tx | Tx |
|
|
|
+| kea | Kabuverdianu | Latn | Sp | \-- |
|
|
|
+| khk | Halh Mongolian | Cyrl | Sp, Tx | Tx |
|
|
|
+| khm | Khmer | Khmr | Sp, Tx | Tx |
|
|
|
+| kir | Kyrgyz | Cyrl | Sp, Tx | Tx |
|
|
|
+| kor | Korean | Kore | Sp, Tx | Sp, Tx |
|
|
|
+| lao | Lao | Laoo | Sp, Tx | Tx |
|
|
|
+| lit | Lithuanian | Latn | Sp, Tx | Tx |
|
|
|
+| ltz | Luxembourgish | Latn | Sp | \-- |
|
|
|
+| lug | Ganda | Latn | Sp, Tx | Tx |
|
|
|
+| luo | Luo | Latn | Sp, Tx | Tx |
|
|
|
+| lvs | Standard Latvian | Latn | Sp, Tx | Tx |
|
|
|
+| mai | Maithili | Deva | Sp, Tx | Tx |
|
|
|
+| mal | Malayalam | Mlym | Sp, Tx | Tx |
|
|
|
+| mar | Marathi | Deva | Sp, Tx | Tx |
|
|
|
+| mkd | Macedonian | Cyrl | Sp, Tx | Tx |
|
|
|
+| mlt | Maltese | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| mni | Meitei | Beng | Sp, Tx | Tx |
|
|
|
+| mya | Burmese | Mymr | Sp, Tx | Tx |
|
|
|
+| nld | Dutch | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| nno | Norwegian Nynorsk | Latn | Sp, Tx | Tx |
|
|
|
+| nob | Norwegian Bokmål | Latn | Sp, Tx | Tx |
|
|
|
+| npi | Nepali | Deva | Sp, Tx | Tx |
|
|
|
+| nya | Nyanja | Latn | Sp, Tx | Tx |
|
|
|
+| oci | Occitan | Latn | Sp | \-- |
|
|
|
+| ory | Odia | Orya | Sp, Tx | Tx |
|
|
|
+| pan | Punjabi | Guru | Sp, Tx | Tx |
|
|
|
+| pbt | Southern Pashto | Arab | Sp, Tx | Tx |
|
|
|
+| pes | Western Persian | Arab | Sp, Tx | Sp, Tx |
|
|
|
+| pol | Polish | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| por | Portuguese | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| ron | Romanian | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| rus | Russian | Cyrl | Sp, Tx | Sp, Tx |
|
|
|
+| slk | Slovak | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| slv | Slovenian | Latn | Sp, Tx | Tx |
|
|
|
+| sna | Shona | Latn | Sp, Tx | Tx |
|
|
|
+| snd | Sindhi | Arab | Sp, Tx | Tx |
|
|
|
+| som | Somali | Latn | Sp, Tx | Tx |
|
|
|
+| spa | Spanish | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| srp | Serbian | Cyrl | Sp, Tx | Tx |
|
|
|
+| swe | Swedish | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| swh | Swahili | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| tam | Tamil | Taml | Sp, Tx | Tx |
|
|
|
+| tel | Telugu | Telu | Sp, Tx | Sp, Tx |
|
|
|
+| tgk | Tajik | Cyrl | Sp, Tx | Tx |
|
|
|
+| tgl | Tagalog | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| tha | Thai | Thai | Sp, Tx | Sp, Tx |
|
|
|
+| tur | Turkish | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| ukr | Ukrainian | Cyrl | Sp, Tx | Sp, Tx |
|
|
|
+| urd | Urdu | Arab | Sp, Tx | Sp, Tx |
|
|
|
+| uzn | Northern Uzbek | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| vie | Vietnamese | Latn | Sp, Tx | Sp, Tx |
|
|
|
+| xho | Xhosa | Latn | Sp | \-- |
|
|
|
+| yor | Yoruba | Latn | Sp, Tx | Tx |
|
|
|
+| yue | Cantonese | Hant | Sp, Tx | Tx |
|
|
|
+| zlm | Colloquial Malay | Latn | Sp | \-- |
|
|
|
+| zsm | Standard Malay | Latn | Tx | Tx |
|
|
|
+| zul | Zulu | Latn | Sp, Tx | Tx |
|
|
|
+
|
|
|
+
|
|
|
+Note that seamlessM4T-medium supports 200 languages in the text modality, and is based on NLLB-200 (see full list in [asset card](src/seamless_communication/cards/unity_nllb-200.yaml))
|
|
|
+
|
|
|
+## Citation
|
|
|
+For *UnitY*, please cite :
|
|
|
+```bibtex
|
|
|
+@inproceedings{inaguma-etal-2023-unity,
|
|
|
+ title="{U}nit{Y}: Two-pass Direct Speech-to-speech Translation with Discrete Units",
|
|
|
+ author="Inaguma, Hirofumi and Popuri, Sravya and Kulikov, Ilia and Chen, Peng-Jen and Wang, Changhan and Chung, Yu-An and Tang, Yun and Lee, Ann and Watanabe, Shinji and Pino, Juan",
|
|
|
+ booktitle="Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers)",
|
|
|
+ year="2023",
|
|
|
+ url="https://aclanthology.org/2023.acl-long.872",
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+For SeamlessM4T v1, please cite :
|
|
|
+```bibtex
|
|
|
+@article{seamlessm4t2023,
|
|
|
+ title={SeamlessM4T: Massively Multilingual \& Multimodal Machine Translation},
|
|
|
+ author={{Seamless Communication}, Lo\"{i}c Barrault, Yu-An Chung, Mariano Cora Meglioli, David Dale, Ning Dong, Paul-Ambroise Duquenne, Hady Elsahar, Hongyu Gong, Kevin Heffernan, John Hoffman, Christopher Klaiber, Pengwei Li, Daniel Licht, Jean Maillard, Alice Rakotoarison, Kaushik Ram Sadagopan, Guillaume Wenzek, Ethan Ye, Bapi Akula, Peng-Jen Chen, Naji El Hachem, Brian Ellis, Gabriel Mejia Gonzalez, Justin Haaheim, Prangthip Hansanti, Russ Howes, Bernie Huang, Min-Jae Hwang, Hirofumi Inaguma, Somya Jain, Elahe Kalbassi, Amanda Kallet, Ilia Kulikov, Janice Lam, Daniel Li, Xutai Ma, Ruslan Mavlyutov, Benjamin Peloquin, Mohamed Ramadan, Abinesh Ramakrishnan, Anna Sun, Kevin Tran, Tuan Tran, Igor Tufanov, Vish Vogeti, Carleigh Wood, Yilin Yang, Bokai Yu, Pierre Andrews, Can Balioglu, Marta R. Costa-juss\`{a} \footnotemark[3], Onur \,{C}elebi,Maha Elbayad,Cynthia Gao, Francisco Guzm\'an, Justine Kao, Ann Lee, Alexandre Mourachko, Juan Pino, Sravya Popuri, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Paden Tomasello, Changhan Wang, Jeff Wang, Skyler Wang},
|
|
|
+ journal={ArXiv},
|
|
|
+ year={2023}
|
|
|
+}
|
|
|
+```
|
|
|
+
|
|
|
+For SeamlessM4T v2, please cite :
|
|
|
+```bibtex
|
|
|
+@inproceedings{seamless2023,
|
|
|
+ title="Seamless: Multilingual Expressive and Streaming Speech Translation",
|
|
|
+ author="{Seamless Communication}, Lo{\"i}c Barrault, Yu-An Chung, Mariano Coria Meglioli, David Dale, Ning Dong, Mark Duppenthaler, Paul-Ambroise Duquenne, Brian Ellis, Hady Elsahar, Justin Haaheim, John Hoffman, Min-Jae Hwang, Hirofumi Inaguma, Christopher Klaiber, Ilia Kulikov, Pengwei Li, Daniel Licht, Jean Maillard, Ruslan Mavlyutov, Alice Rakotoarison, Kaushik Ram Sadagopan, Abinesh Ramakrishnan, Tuan Tran, Guillaume Wenzek, Yilin Yang, Ethan Ye, Ivan Evtimov, Pierre Fernandez, Cynthia Gao, Prangthip Hansanti, Elahe Kalbassi, Amanda Kallet, Artyom Kozhevnikov, Gabriel Mejia, Robin San Roman, Christophe Touret, Corinne Wong, Carleigh Wood, Bokai Yu, Pierre Andrews, Can Balioglu, Peng-Jen Chen, Marta R. Costa-juss{\`a}, Maha Elbayad, Hongyu Gong, Francisco Guzm{\'a}n, Kevin Heffernan, Somya Jain, Justine Kao, Ann Lee, Xutai Ma, Alex Mourachko, Benjamin Peloquin, Juan Pino, Sravya Popuri, Christophe Ropers, Safiyyah Saleem, Holger Schwenk, Anna Sun, Paden Tomasello, Changhan Wang, Jeff Wang, Skyler Wang, Mary Williamson",
|
|
|
+ journal={ArXiv},
|
|
|
+ year={2023}
|
|
|
+}
|
|
|
+```
|
|
|
+
|

 Ning
Ning
{kind=link}

{kind=link}